Have you ever wondered about the origins of the technologies that shape our digital lives today? It's pretty amazing, actually, how some ideas start small and grow to become truly massive, don't you think? Like, more than 80% of all Fortune 100 companies trust and use Kafka, which is a big deal, really.
It's fascinating to look back at how something so widely adopted got its start. What problems was it trying to fix back then? Who were the people who first imagined it? This look at Kafka's early years gives us a better appreciation for what it does now.
Learning about the initial thinking behind a system like Apache Kafka can really help you understand its core principles better. It's almost like seeing the blueprint before the building went up, you know? This post will help us learn about Apache Kafka from its very first steps.
Table of Contents
- The Birth of a Streaming Platform
- Why LinkedIn Needed Something New
- Early Core Ideas and Design Choices
- How Kafka Solved Early Data Challenges
- From Internal Tool to Open Source Project
- Benefits of Understanding Kafka's Past for Today's Use
- Frequently Asked Questions About Kafka's Early Days
- Looking Ahead from the Early Days
The Birth of a Streaming Platform
Every big project has a starting point, a moment when someone decided there had to be a better way to do things. For Apache Kafka, that moment came at LinkedIn, a place with a huge amount of data moving around all the time. So, it's pretty clear why they needed something special.
Back in 2010, a group of smart people at LinkedIn began working on a new kind of system. They wanted something that could handle vast amounts of event data, things like user actions, website clicks, and system logs, all in real time. This was a rather big challenge for the existing tools.
The name "Kafka" itself is interesting, isn't it? It was named after Franz Kafka, the author, because the creators felt it was a system optimized for writing. This choice of name, you know, gives it a bit of a unique character right from the start.
The folks involved, including Jay Kreps, Neha Narkhede, and Jun Rao, saw a growing need for a different approach to data handling. They noticed that as LinkedIn grew, the ways they were moving information around just weren't keeping up. This was a real problem, honestly.
They envisioned a system that could act as a central nervous system for all of LinkedIn's data. Something that could collect information from many sources and deliver it to many destinations without missing a beat. That, is that, a pretty ambitious goal for the time.
The core idea was to build a platform that could handle the sheer volume and speed of data generated by a large online service. This meant thinking differently about how data was stored, transmitted, and consumed. It was quite a shift in thinking, you know.
Why LinkedIn Needed Something New
LinkedIn, as a social network for professionals, generates an incredible volume of data every second. Think about all the profile views, connection requests, job applications, and messages. All these actions create "events" that need to be processed, very quickly.
Before Kafka, LinkedIn used a mix of different systems to move this data around. There were message queues, log aggregators, and custom scripts, basically. This setup, you know, worked for a while, but it started to show its limits as the company grew bigger and bigger.
The main problem was that each new data source or data consumer needed its own special connection. It was like having a spaghetti mess of wires, where adding one new device meant rewiring a lot of other things. This made it really hard to scale and manage, obviously.
Imagine trying to add a new analytics tool. You would have to connect it directly to every single system that produced data. Then, if you added another data source, you'd have to update all your existing analytics tools. This process was slow and prone to errors, which was a real pain, you know.
The existing systems also had trouble keeping up with the sheer speed of data. Real-time insights were becoming more important, but the tools they had couldn't deliver information fast enough. They needed a way to process events as they happened, virtually immediately.
They also wanted a system that could store these events for a period, not just pass them along. This ability to "replay" events was quite important for things like analytics, data warehousing, and recovering from issues. That, is that, a pretty useful feature, you know.
The engineers also faced issues with data loss and inconsistency. With so many separate systems, it was hard to guarantee that all data made it to its destination or that everyone had the same, correct version of information. They needed something more reliable, more or less.
The goal was to move away from point-to-point integrations and towards a central, shared system. This would simplify the data flow and allow teams to work more independently. It was about creating a more organized and efficient data landscape, in a way.
Early Core Ideas and Design Choices
The people building Kafka had some very specific goals in mind. They wanted a distributed streaming platform, which means it would run across many computers, working together. This design choice, you know, was key for handling so much data.
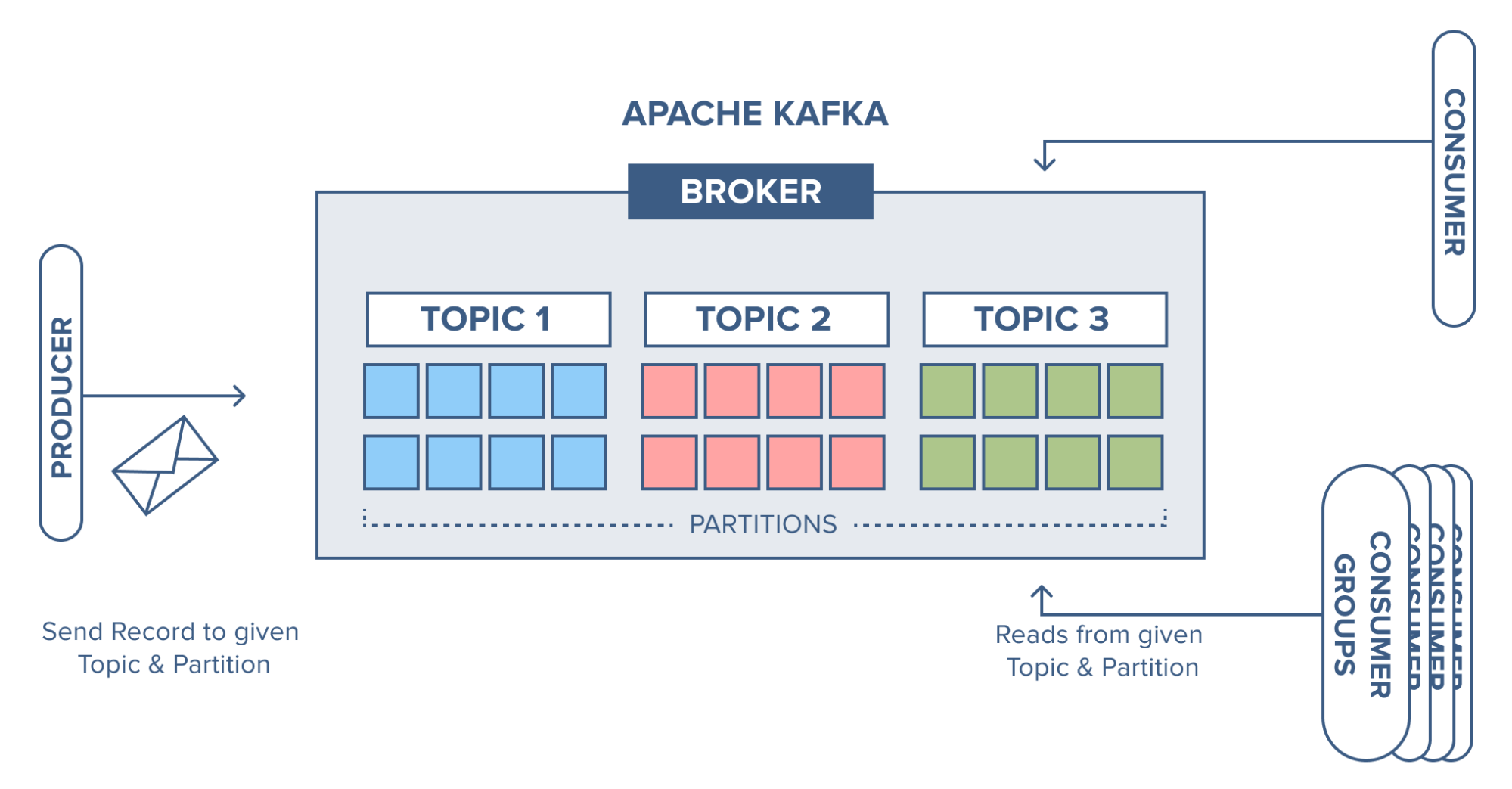
One of the core ideas was the concept of a "commit log" or "distributed log." This is a simple but powerful idea: all events are written in order to an append-only log. This means new events are always added to the end, never changing what came before. It's very much like a ledger, in a way.
This append-only design offered a few big advantages. It made data ordering clear, which is crucial for many applications. It also made the system very good at handling lots of writes, as it just had to add to the end of a file. This helped with speed, basically.
They also decided to make it a publish-subscribe system. Data producers (like a website server recording clicks) would "publish" events to specific topics. Data consumers (like an analytics tool) would "subscribe" to those topics to get the events they needed. This separation was quite clever.
This publish-subscribe model meant that producers didn't need to know who was reading their data, and consumers didn't need to know who was writing it. This made the system much more flexible and easier to expand. It was a bit like a bulletin board where anyone can post and anyone can read, you know.
Another big decision was to keep the system very fast. They designed it to use sequential disk writes, which are much quicker than random writes. This, you know, helped Kafka achieve its impressive speed for moving